Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka's server-side cluster technology..
Simply so, what is the use of Kafka streams?
Kafka Streams is a library for building streaming applications, specifically applications that transform input Kafka topics into output Kafka topics (or calls to external services, or updates to databases, or whatever). It lets you do this with concise code in a way that is distributed and fault-tolerant.
what is Kafka streams API? The Kafka Streams API allows you to create real-time applications that power your core business. It is the easiest to use yet the most powerful technology to process data stored in Kafka. It gives us the implementation of standard classes of Kafka.
Similarly, you may ask, what is the difference between Kafka and Kafka streams?
Every topic in Kafka is split into one or more partitions. Kafka partitions data for storing, transporting, and replicating it. Kafka Streams partitions data for processing it. In both cases, this partitioning enables elasticity, scalability, high performance, and fault tolerance.
How do I create a Kafka stream?
This quick start follows these steps:
- Start a Kafka cluster on a single machine.
- Write example input data to a Kafka topic, using the so-called console producer included in Kafka.
- Process the input data with a Java application that uses the Kafka Streams library.
Related Question Answers
Is Kafka streaming?
Kafka Streams is a library for building streaming applications, specifically applications that transform input Kafka topics into output Kafka topics (or calls to external services, or updates to databases, or whatever). It lets you do this with concise code in a way that is distributed and fault-tolerant.Is Kafka open source?
Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.When should I use Kafka?
Kafka is used for real-time streams of data, to collect big data, or to do real time analysis (or both). Kafka is used with in-memory microservices to provide durability and it can be used to feed events to CEP (complex event streaming systems) and IoT/IFTTT-style automation systems.How do I run Kafka on Windows?
D. Running a Kafka Server - Go to your Kafka installation directory: C:kafka_2.11-0.9.0.0
- Open a command prompt here by pressing Shift + right click and choose the “Open command window here” option).
- Now type . inwindowskafka-server-start. bat . configserver. properties and press Enter.
How does Kafka work?
How does it work? Applications (producers) send messages (records) to a Kafka node (broker) and said messages are processed by other applications called consumers. Said messages get stored in a topic and consumers subscribe to the topic to receive new messages.Can Kafka transform data?
Kafka Streams API gives applications the stream processing capabilities to transform data, one message or event at a time. These transformations can include joining multiple data sources, filtering data, and aggregating data over a period of time.What is ZooKeeper server?
ZooKeeper is an open source Apache project that provides a centralized service for providing configuration information, naming, synchronization and group services over large clusters in distributed systems. The goal is to make these systems easier to manage with improved, more reliable propagation of changes.What is stream processing in big data?
Stream Processing is a Big data technology. It is used to query continuous data stream and detect conditions, quickly, within a small time period from the time of receiving the data.Is Kafka stateless?
Kafka Streams is a java library used for analyzing and processing data stored in Apache Kafka. As with any other stream processing framework, it's capable of doing stateful and/or stateless processing on real-time data.Is Kafka an API?
Kafka Streams API Kafka Streams (or Streams API) is a stream-processing library written in Java. It was added in the Kafka 0.10. For fault-tolerance, all updates to local state stores are also written into a topic in the Kafka cluster. This allows recreating state by reading those topics and feed all data into RocksDB.Can Kafka call an API?
It will let you produce messages to a Kafka topic with a REST API in JSON or Avro. Alternatively, if you don't want to use Confluent REST Proxy for Kafka, you can run a web application using a Web Framework which will call into a Kafka Client library during an HTTP request from the client.Why is Kafka connected?
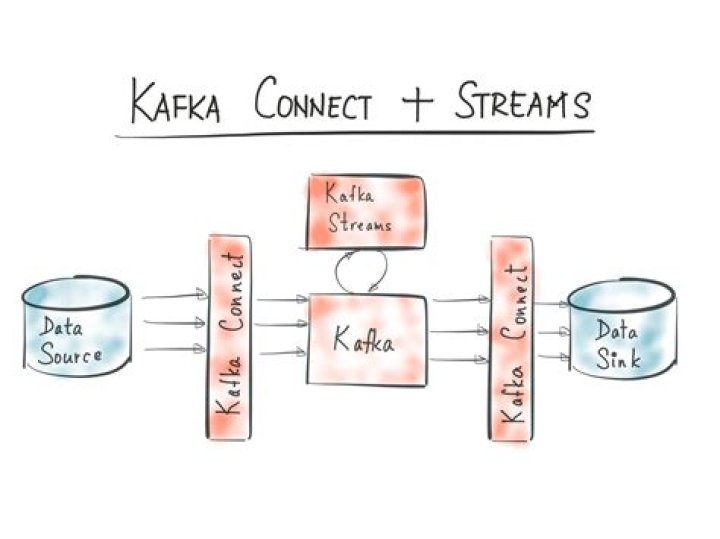
Kafka Connect is an open source framework, built as another layer on core Apache Kafka, to support large scale streaming data: import from any external system (called Source) like mysql,hdfs,etc to Kafka broker cluster. export from Kafka cluster to any external system (called Sink) like hdfs,s3,etc.What is a KTable?
A KTable is an abstraction of a changelog stream, where each data record represents an update.What is K table?
KTable is an abstraction of a changelog stream from a primary-keyed table. Each record in this changelog stream is an update on the primary-keyed table with the record key as the primary key.Is Kafka a Amqp?
Kafka is a newer tool, released in 2011, which, from the onset, was built for streaming scenarios. RabbitMQ is a general purpose message broker that supports protocols including, MQTT, AMQP, and STOMP. Kafka is a message bus developed for high-ingress data replay and streams.What is Kafka AWS?
Apache Kafka is an open-source platform for building real-time streaming data pipelines and applications. With Amazon MSK, you can use native Apache Kafka APIs to populate data lakes, stream changes to and from databases, and power machine learning and analytics applications.What is ZooKeeper in Kafka?
ZooKeeper is a software built by Apache which is used to maintain configuration and naming data along with providing robust and flexible synchronization in the distributed systems. It acts as a centralized service and helps to keep track of the Kafka cluster nodes status, Kafka topics, and partitions.Is Kafka real time?
Apache Kafka is a distributed streaming platform. At its core, it allows systems that generate data (called Producers) to persist their data in real-time in an Apache Kafka Topic. Behind the scenes, Kafka is distributed, scales well, replicates data across brokers (servers), can survive broker downtime, and much more.What is a Kafka topology?
A topology is an acyclic graph of sources, processors, and sinks. A source is a node in the graph that consumes one or more Kafka topics and forwards them to its successor nodes. Finally, a sink is a node in the graph that receives records from upstream nodes and writes them to a Kafka topic.