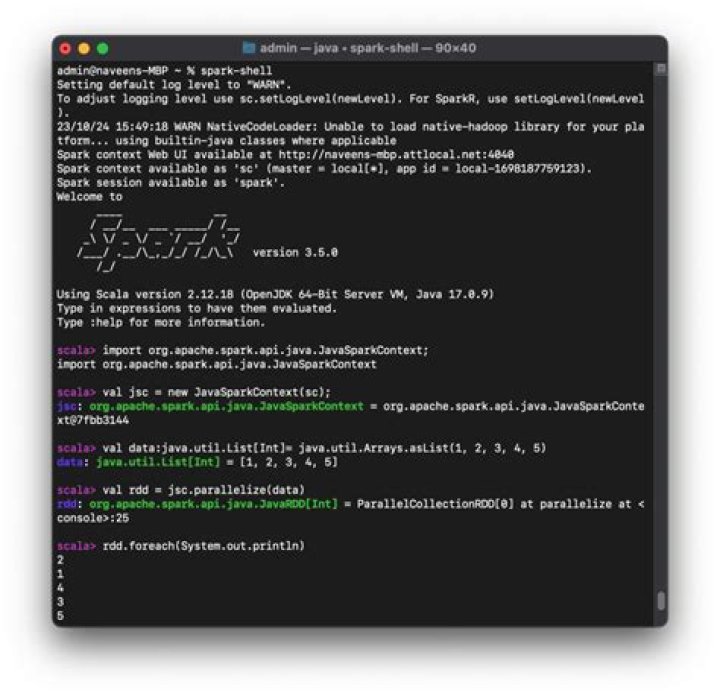
What is JavaRDD?
.
Similarly, you may ask, how do I convert Javapdrd to JavaRDD?
A JavaPairRDD is a key/value mapping between the first and second column, unlike a normal RDD. You possibly want to drop off the first column from the JavaPairRDD, returning just JavaRDD with just the value column. To to this, simply run something like: JavaRDD newRDD = esRDD.
Also, does spark support Java 11? Spark uses Hadoop's client libraries for HDFS and YARN. Downloads are pre-packaged for a handful of popular Hadoop versions. Spark runs on Java 8/11, Scala 2.12, Python 2.7+/3.4+ and R 3.1+. Java 8 prior to version 8u92 support is deprecated as of Spark 3.0.
Considering this, what is Java RDD?
Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. It is an immutable distributed collection of objects. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes. Formally, an RDD is a read-only, partitioned collection of records.
What is spark mapToPair?
mapToPair. It is similar to map transformation; however, this transformation produces PairRDD , that is, an RDD consisting of key and value pairs. This transformation is specific to Java RDDs. With other RDDs, map transformation can perform both ( map and mapToPair() ) of the tasks.
Related Question AnswersWhat is JavaSparkContext?
JavaSparkContext: A Java-friendly version of [[org. JavaRDD]]s and works with Java collections instead of Scala ones. Only one SparkContext may be active per JVM. You must stop() the active SparkContext before creating a new one.What is SC parallelize in spark?
The sc. parallelize() method is the SparkContext's parallelize method to create a parallelized collection. This allows Spark to distribute the data across multiple nodes, instead of depending on a single node to process the data: Now that we have createdHow is RDD resilient?
The key idea of spark is Resilient Distributed Datasets (RDD); it supports in-memory processing computation. This means, it stores the state of memory as an object across the jobs and the object is sharable between those jobs. Data sharing in memory is 10 to 100 times faster than network and Disk.What is the full form of RDD?
The full form of RDD is a resilient distributed dataset. It is a representation of data located on a network which is: Immutable – You can operate on the RDD to produce another RDD but you can't alter it. Partitioned / Parallel – The data located on RDD is operated in parallel.Is RDD a memory?
All the RDD is stored in-memory, while we use cache() method. As RDD stores the value in memory, the data which does not fit in memory is either recalculated or the excess data is sent to disk. The RDDs can also be stored in-memory while we use persist() method. Also, we can use it across parallel operations.How does RDD store data?
The key idea of spark is Resilient Distributed Datasets (RDD); it supports in-memory processing computation. This means, it stores the state of memory as an object across the jobs and the object is sharable between those jobs. Data sharing in memory is 10 to 100 times faster than network and Disk.What is the difference between RDD and DataFrame?
RDD – RDD is a distributed collection of data elements spread across many machines in the cluster. RDDs are a set of Java or Scala objects representing data. DataFrame – A DataFrame is a distributed collection of data organized into named columns. It is conceptually equal to a table in a relational database.Why is RDD immutable?
RDDs are not just immutable but a deterministic function of their input. That means RDD can be recreated at any time. This helps in taking advantage of caching, sharing and replication. Immutable data can as easily live in memory as on disk.Why is RDD resilient?
Resilient because RDDs are immutable(can't be modified once created) and fault tolerant, Distributed because it is distributed across cluster and Dataset because it holds data. RDDs are automatically distributed across the network by means of Partitions.What is RDD partition?
Resilient Distributed Datasets (RDD) is a simple and immutable distributed collection of objects. Each RDD is split into multiple partitions which may be computed on different nodes of the cluster. In Spark, every function is performed on RDDs only.What are the features of spark RDD?
3. Spark RDD – Prominent Features- 3.1. In-Memory. It is possible to store data in spark RDD.
- 3.2. Lazy Evaluations.
- 3.3. Immutable and Read-only.
- 3.4. Cacheable or Persistence.
- 3.5. Partitioned.
- 3.6. Parallel.
- 3.7. Fault Tolerance.
- 3.8. Location Stickiness.
How do I run spark shell?
Run Spark from the Spark Shell- Navigate to the Spark-on-YARN installation directory, and insert your Spark version into the command. cd /opt/mapr/spark/spark-<version>/
- Issue the following command to run Spark from the Spark shell: On Spark 2.0.1 and later: ./bin/spark-shell --master yarn --deploy-mode client.
Can I run spark locally?
Spark can be run using the built-in standalone cluster scheduler in the local mode. This means that all the Spark processes are run within the same JVM-effectively, a single, multithreaded instance of Spark. The local mode is very used for prototyping, development, debugging, and testing.Does pySpark install spark?
Install pySpark To install Spark, make sure you have Java 8 or higher installed on your computer. Then, visit the Spark downloads page. Select the latest Spark release, a prebuilt package for Hadoop, and download it directly. This way, you will be able to download and use multiple Spark versions.How do you check if the spark is installed or not?
2 Answers- Open Spark shell Terminal and enter command.
- sc.version Or spark-submit --version.
- The easiest way is to just launch “spark-shell” in command line. It will display the.
- current active version of Spark.
How do I run Apache spark locally?
The following steps show how to install Apache Spark.- Step 1: Verifying Java Installation.
- Step 2: Verifying Scala installation.
- Step 3: Downloading Scala.
- Step 4: Installing Scala.
- Step 5: Downloading Apache Spark.
- Step 6: Installing Spark.
- Step 7: Verifying the Spark Installation.
Can spark run on Windows?
A Spark application can be a Windows-shell script or it can be a custom program in written Java, Scala, Python, or R. You need Windows executables installed on your system to run these applications.Is spark open source?
Apache Spark is an open-source distributed general-purpose cluster-computing framework. Originally developed at the University of California, Berkeley's AMPLab, the Spark codebase was later donated to the Apache Software Foundation, which has maintained it since.How do I master Apache spark?
Step by Step Guide to Master Apache Spark- Step 1: Understanding Apache Spark Architecture.
- Step 2: Get hold of the Programming Language to develop spark applications.
- Step 3: Understanding Apache Spark's key terms.
- Step 4: Mastering the Storage systems used for Spark.
- Step 5: Learning Apache Spark core in-depth.




