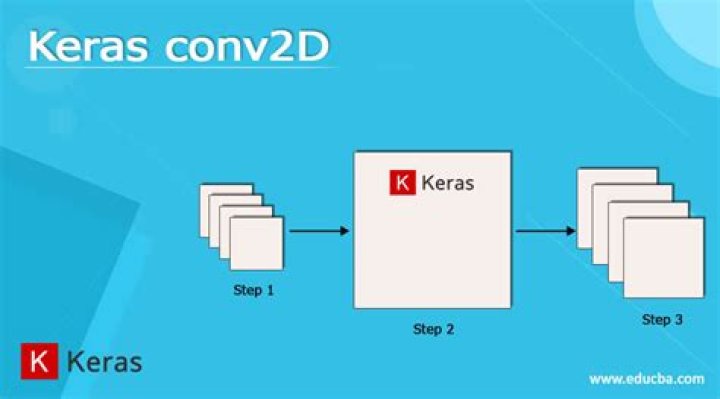
Conv2D Class. Keras Conv2D is a 2D Convolution Layer, this layer creates a convolution kernel that is wind with layers input which helps produce a tensor of outputs..
Considering this, what is the difference between Conv1D and Conv2D?
With Conv1D, one dimension only is used, so the convolution operates on the first axis (size 68 ). With Conv2D, two dimensions are used, so the convolution operates on the two axis defining the data (size (68,2) )
Also Know, what is kernel size in Conv2D? The kernel size here refers to the widthxheight of the filter mask. The max pooling layer, for example, returns the pixel with maximum value from a set of pixels within a mask (kernel). That kernel is swept across the input, subsampling it.
Similarly, it is asked, what are filters in Conv2D?
The most common type of convolution that is used is the 2D convolution layer, and is usually abbreviated as conv2D. A filter or a kernel in a conv2D layer has a height and a width. They are generally smaller than the input image and so we move them across the whole image.
What is maxpooling1d?
Max pooling is a sample-based discretization process. The objective is to down-sample an input representation (image, hidden-layer output matrix, etc.), reducing its dimensionality and allowing for assumptions to be made about features contained in the sub-regions binned.
Related Question Answers
What is Conv1D?
Conv1D and Conv2D summarize (convolve) along one or two dimensions. For instance, you could convolve a vector into a shorter vector as followss.How does 3d convolution work?
In 3D convolution, a 3D filter can move in all 3-direction (height, width, channel of the image). At each position, the element-wise multiplication and addition provide one number. Since the filter slides through a 3D space, the output numbers are arranged in a 3D space as well. The output is then a 3D data.What is 2d convolution?
A 2D convolution layer means that the input of the convolution operation is three-dimensional, for example, a color image which has a value for each pixel across three layers: red, blue and green. However, it is called a “2D convolution” because the movement of the filter across the image happens in two dimensions.What is 2d CNN?
CNN stands for Convolutional Neural Network which is a specialized neural network for processing data that has an input shape like a 2D matrix like images. CNN's are typically used for image detection and classification.What is a 3d CNN?
In a 3D CNN, the kernels move through three dimensions of data (height, length, and depth) and produce 3D activation maps.What is a 1d convolution?
Convolution op- erates on two signals (in 1D) or two images (in 2D): you can think of one as the “input” signal (or image), and the other (called the kernel) as a “filter” on the input image, pro- ducing an output image (so convolution takes two images as input and produces a third as output).What is kernel size in CNN?
In a CNN context, people sometimes use "kernel size" to mean the size of a convolutional filter, and likewise a "kernel" is the filter itself.What is 1d convolutional neural network?
What are 1D Convolutional Neural Networks? Convolutional Neural Network (CNN) models were developed for image classification, in which the model accepts a two-dimensional input representing an image's pixels and color channels, in a process called feature learning.What is convolution of an image?
Convolution is a simple mathematical operation which is fundamental to many common image processing operators. Convolution provides a way of `multiplying together' two arrays of numbers, generally of different sizes, but of the same dimensionality, to produce a third array of numbers of the same dimensionality.What is 3x3 convolution?
3x3 convolution filters — A popular choice. IceCream Labs. Aug 20, 2018 · 2 min read. In image processing, a kernel, convolution matrix, or mask is a small matrix. It is used for blurring, sharpening, embossing, edge detection, and more.What is ReLU in deep learning?
ReLU stands for rectified linear unit, and is a type of activation function. Mathematically, it is defined as y = max(0, x). Visually, it looks like the following: ReLU is the most commonly used activation function in neural networks, especially in CNNs.Are convolutional filters linear?
Linear filtering of an image is accomplished through an operation called convolution. Convolution is a neighborhood operation in which each output pixel is the weighted sum of neighboring input pixels. The matrix of weights is called the convolution kernel, also known as the filter.What is the use of convolution?
Convolution is a mathematical way of combining two signals to form a third signal. It is the single most important technique in Digital Signal Processing. Convolution is important because it relates the three signals of interest: the input signal, the output signal, and the impulse response.Is TensorFlow open source?
TensorFlow is an open source software library for numerical computation using data-flow graphs. TensorFlow is cross-platform. It runs on nearly everything: GPUs and CPUs—including mobile and embedded platforms—and even tensor processing units (TPUs), which are specialized hardware to do tensor math on.What is number of filters in convolutional layer?
The number of filters is a hyper-parameter that can be tuned. The number of neurons in a convolutional layer equals to the size of the output of the layer. In the case of images, it's the size of the feature map.What is padding in keras?
padding: one of "valid" or "same" (case-insensitive). data_format: A string, one of "channels_last" or "channels_first" . The ordering of the dimensions in the inputs. It defaults to the image_data_format value found in your Keras config file at ~/. keras/keras.What is the size of kernel?
How can a linux kernel be so small? An ordinary stable 3* kernel is about 70 mb now. But there are little linux distributions of 30-10 mb with software and other stuff running out of the box.What does batch normalization do?
From Wikipedia, the free encyclopedia. Batch normalization is a technique for improving the speed, performance, and stability of artificial neural networks. Batch normalization was introduced in a 2015 paper. It is used to normalize the input layer by adjusting and scaling the activations.How do I choose a kernel size?
A common choice is to keep the kernel size at 3x3 or 5x5. The first convolutional layer is often kept larger. Its size is less important as there is only one first layer, and it has fewer input channels: 3, 1 by color.