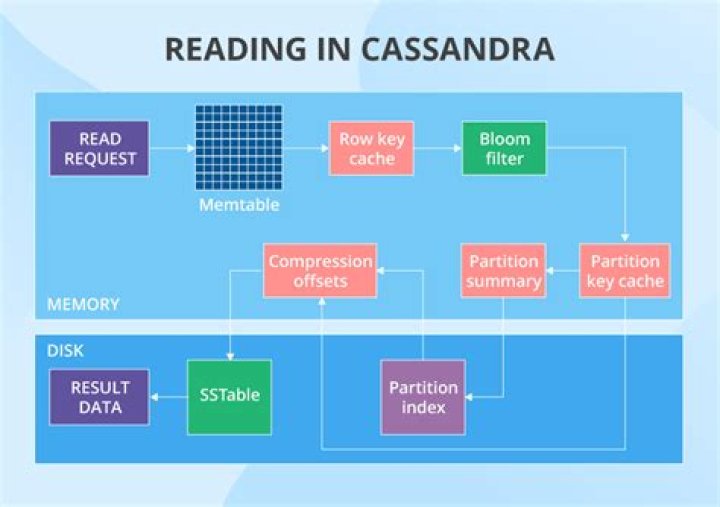
When a write occurs, Cassandra stores the data in a structure in memory, the memtable, and also appends writes to the commit log on disk. The memtable is a write-back cache of data partitions that Cassandra looks up by key. The commit log is for recovering the data in memtable in the event of a hardware failure..
Then, what is CommitLog in Cassandra?
CommitLog. Commitlogs are an append only log of all mutations local to a Cassandra node. Any data written to Cassandra will first be written to a commit log before being written to a memtable. Commitlog segments can be archived, deleted, or recycled once all its data has been flushed to SSTables.
how does Cassandra work? Cassandra is a peer-to-peer distributed system made up of a cluster of nodes in which any node can accept a read or write request. Similar to Amazon's Dynamo DB, every node in the cluster communicates state information about itself and other nodes using the peer-to-peer gossip communication protocol.
Beside above, what is Memtable in Cassandra?
Memtable — a memory cache to store the in memory copy of the data. Each node has a memtable for each CQL table. Cassandra also stores the data in a memory structure called memtable and to provide configurable durability. The memtable is a write-back cache of data partitions that Cassandra looks up by key.
How does Cassandra write data?
When we start the writing data into Cassandra, it follows these steps:
- It connected to any node in the cluster which is called Coordinator.
- It Logging data into commit log.
- Now every data write into the MemTable which is created in memory with the TimeStamp.
Related Question Answers
Where is data stored in Cassandra?
All cassandra data is persisted in SSTables(Sorted String tables) inside data directory. Default location of data directory is $CASSANDRA_HOME/data/data . You can change it using data_file_directorie In order to get optimal performance from cassandra, its important to understand how it stores the data on disk.What is the use of commit log?
The commit log is for recovering the data in memtable in the event of a hardware failure. SSTables are immutable, not written to again after the memtable is flushed.How does Cassandra store data internally?
In Cassandra Data model, Cassandra database stores data via Cassandra Clusters. Clusters are basically the outermost container of the distributed Cassandra database. The database is distributed over several machines operating together. Every machine acts as a node and has their own replica in case of failures.What does Nodetool flush do?
nodetool flush. Flushes one or more tables from the memtable to SSTables on disk. Flushes one or more tables from the memtable to SSTables on disk. OpsCenter provides a flush option in the Nodes UI for Flushing tables.What type of data model does Cassandra use?
Cassandra Data Model. Cassandra is a NoSQL database, which is a key-value store. Some of the features of Cassandra data model are as follows: Data in Cassandra is stored as a set of rows that are organized into tables.How does Cassandra replication work?
Cassandra Data Replication. In a distributed system like Cassandra, data replication enables high availability and durability. Cassandra replicates rows in a column family on to multiple endpoints based on the replication strategy associated to its keyspace. It is commonly used when nodes are in a single data center.What port does Cassandra use for communication?
By default, Cassandra uses 7000 for cluster communication (7001 if SSL is enabled), 9042 for native protocol clients, and 7199 for JMX. The internode communication and native protocol ports are configurable in the Cassandra Configuration File.What is column family in Cassandra?
A column family is a container for an ordered collection of rows. In Cassandra, although the column families are defined, the columns are not. You can freely add any column to any column family at any time. Relational tables define only columns and the user fills in the table with values.What is Memtable?
A memtable is basically a write-back cache of data rows that can be looked up by key i.e. unlike a write-through cache, writes are batched up in the memtable until it is full, when a memtable is full, and it is written to disk as SSTable.What does success means for Cassandra write operation?
Success means data was written to the commit log and the memtable. The coordinator node forwards the write to replicas of that row.What is compaction in Cassandra?
The concept of compaction is used for different kinds of operations in Cassandra, the common thing about these operations is that it takes one or more sstables and output new sstables. triggered automatically in Cassandra. Major compaction. a user executes a compaction over all sstables on the node.How is data written?
When your computer stores data on its hard drive, it doesn't just throw magnetized nails into a box, all jumbled up together. The data is stored in a very orderly pattern on each platter. Bits of data are arranged in concentric, circular paths called tracks. Each track is broken up into smaller areas called sectors.How does update work in Cassandra?
Update Data Command 'Update' is used to update the data in the Cassandra table. If no results are returned after updating data, it means data is successfully updated otherwise an error will be returned. Column values are changed in 'Set' clause while data is filtered with 'Where' clause.What is the default partitioner in the Apache Cassandra cluster?
The Murmur3Partitioner is currently the default partitioner in Cassandra. Some of the features of this partitioner are: It uses the MurmurHash function. The MurmurHash function is a non-cryptographic hash function that creates a 64-bit hash value of the partition key.What is writeback and write through caches?
Write-back (or Write-behind): Writing is done only to the cache. A modified cache block is written back to the store, just before it is replaced. Write-through: When data is updated, it is written to both the cache and the back-end storage.What is replication factor in Cassandra?
About the Cassandra replication factor The total number of replicas for a keyspace across a Cassandra cluster is referred to as the keyspace's replication factor. A replication factor of one means that there is only one copy of each row in the Cassandra cluster. What is the need of a partition key?
The partition key is responsible for distributing data among nodes. A partition key is the same as the primary key when the primary key consists of a single column. Partition keys belong to a node. Cassandra is organized into a cluster of nodes, with each node having an equal part of the partition key hashes.Is Cassandra difficult to learn?
Is Cassandra hard to learn? Most nosql is easier to learn than relational systems since many of those relational systems have as much as 30 year head start on getting features going. Cassandra isn't too bad. You have to learn to build tables as if you were building around materialized views.Is Cassandra a document database?
NoSQL Database types Columnar Databases – HBase and Cassandra is a type of Columnar database. Document Databases – CouchDB and MongoDB is a type of Document Database. Document databases store and retrieve semi-structured data in the format of documents such as XML, JSON, etc.