HDFS is not a NoSQL. HDFS short for hadoop distributed file system which is the core of hadoop. On the other hand HBase which operates on top of HDFS is a NoSQL..
Simply so, is Hadoop a NoSQL database?
Hadoop is not a type of database, but rather a software ecosystem that allows for massively parallel computing. It is an enabler of certain types NoSQL distributed databases (such as HBase), which can allow for data to be spread across thousands of servers with little reduction in performance.
Likewise, is hive a NoSQL database? Hive and HBase are two different Hadoop based technologies — Hive is an SQL-like engine that runs MapReduce jobs, and HBase is a NoSQL key/value database on Hadoop.
Additionally, is HBase a NoSQL database?
Apache HBase is a column-oriented, NoSQL database built on top of Hadoop (HDFS, to be exact). It is an open source implementation of Google's Bigtable paper. HBase is a top-level Apache project and just released its 1.0 release after many years of development. Data in HBase is broken into tables.
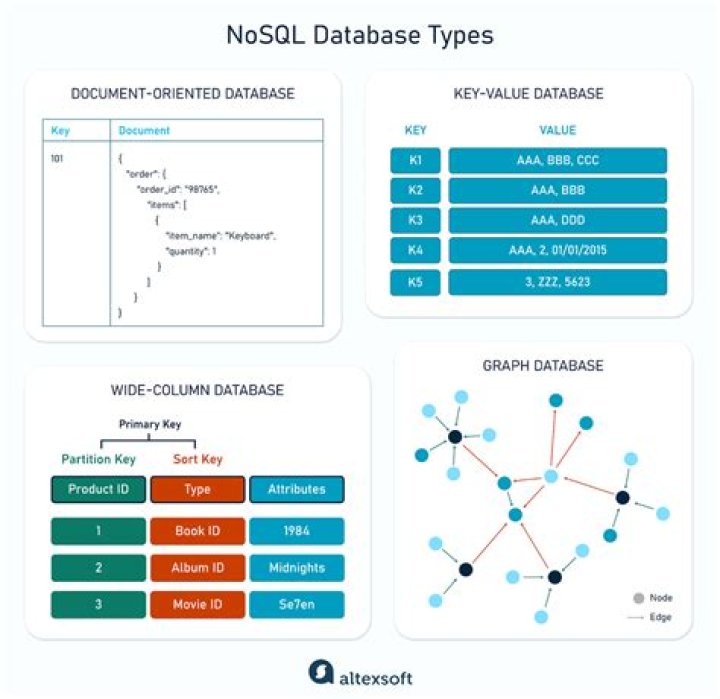
What is NoSQL database in big data?
NoSQL is a database technology driven by Cloud Computing, the Web, Big Data and the Big Users. NoSQL generally scales horizontally and avoids major join operations on the data. NoSQL database can be referred to as structured storage which consists of relational database as the subset.
Related Question Answers
Is Hadoop a data lake?
A data lake is an architecture, while Hadoop is a component of that architecture. In other words, Hadoop is the platform for data lakes. For example, in addition to Hadoop, your data lake can include cloud object stores like Amazon S3 or Microsoft Azure Data Lake Store (ADLS) for economical storage of large files.Does Cassandra run on Hadoop?
Cassandra is mostly considered for real-time processing. Core of Hadoop is HDFS, which is base for other analytical components for handling big data. Cassandra work on top HDFS. Hadoop follows CP, that is consistency and partition tolerance.Is Hadoop dead?
While Hadoop for data processing is by no means dead, Google shows that Hadoop hit its peak popularity as a search term in summer 2015 and its been on a downward slide ever since.Is Hadoop a database?
Hadoop is not a type of database, but rather a software ecosystem that allows for massively parallel computing. It is an enabler of certain types NoSQL distributed databases (such as HBase), which can allow for data to be spread across thousands of servers with little reduction in performance.Is Hadoop SQL?
Hadoop is a distributed computing framework which has its two core components – Hadoop Distributed File System (HDFS) which is a Flat File System and MapReduce for processing data. Hadoop doesn't support OLTP (Real-time Data processing). Due to highly normalized data, SQL performs fast data processing.What is NoSQL database example?
NoSQL is used for Big data and real-time web apps. For example, companies like Twitter, Facebook, Google that collect terabytes of user data every single day. NoSQL database stands for "Not Only SQL" or "Not SQL." Though a better term would NoREL NoSQL caught on. Carl Strozz introduced the NoSQL concept in 1998.Which is best NoSQL database?
Best NoSQL Databases include: Redis, Amazon DynamoDB, Couchbase, Google Cloud Datastore, and MongoDB.What is schema in Hadoop?
Schema on read refers to an innovative data analysis strategy in new data-handling tools like Hadoop and other more involved database technologies. In schema on read, data is applied to a plan or schema as it is pulled out of a stored location, rather than as it goes in.Which NoSQL is easiest to learn?
MongoDB
Is HBase data stored in HDFS?
All HBase data is stored in HDFS files. Region Servers are collocated with the HDFS DataNodes, which enable data locality (putting the data close to where it is needed) for the data served by the RegionServers. HBase data is local when it is written, but when a region is moved, it is not local until compaction.Is MongoDB Hadoop?
MongoDB is a C++ based database, which makes it better at memory handling. Hadoop is a Java-based collection of software that provides a framework for storage, retrieval, and processing.What type of database is HBase?
HBase is a distributed column-oriented database built on top of the Hadoop file system. It is an open-source project and is horizontally scalable. HBase is a data model that is similar to Google's big table designed to provide quick random access to huge amounts of structured data.What is difference between HDFS and HBase?
Hadoop and HBase are both used to store a massive amount of data. But the difference is that in Hadoop Distributed File System (HDFS) data is stored is a distributed manner across different nodes on that network. Whereas, HBase is a database that stores data in the form of columns and rows in a Table.Why do we use HBase?
HBase Use Cases HBase is primarily used to store and process unstructured Hadoop data as a lake. You can also use HBase as your warehouse for all Hadoop data, but we primarily see it used for write-heavy operations.What is difference between Cassandra and MongoDB?
While CQL is similar to SQL in syntax, Cassandra is non-relational, so it has different ways of storing and retrieving data. MongoDB: MongoDB uses JSON-like documents that can have varied structures. Since it is schema-free, you can create documents without having to create the structure for the document first.What is Hdfs in big data?
The Hadoop Distributed File System (HDFS) is the primary data storage system used by Hadoop applications. It employs a NameNode and DataNode architecture to implement a distributed file system that provides high-performance access to data across highly scalable Hadoop clusters.What is zookeeper in Hadoop?
Apache Zookeeper is a coordination service for distributed application that enables synchronization across a cluster. Zookeeper is a Hadoop Admin tool used for managing the jobs in the cluster.Why hive is not a database?
No, we cannot call Apache Hive a relational database, as it is a data warehouse which is built on top of Apache Hadoop for providing data summarization, query and, analysis. It supports queries expressed in a language called HiveQL, which automatically translates SQL-like queries into MapReduce jobs executed on Hadoop.Why pig is used in Hadoop?
Pig is a high level scripting language that is used with Apache Hadoop. Pig enables data workers to write complex data transformations without knowing Java. Pig works with data from many sources, including structured and unstructured data, and store the results into the Hadoop Data File System.