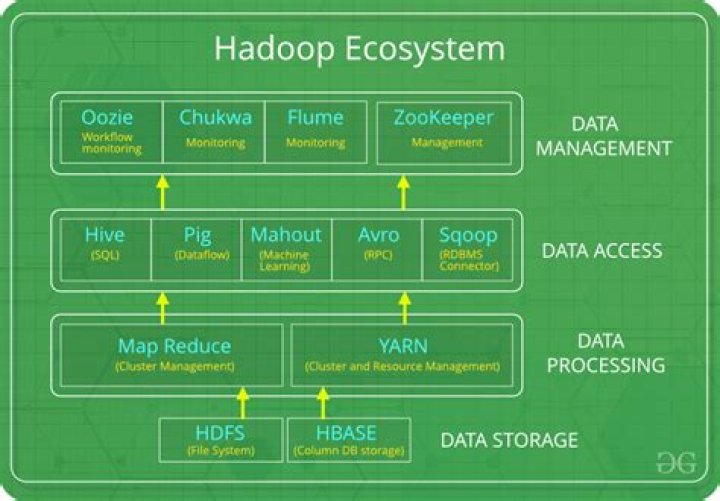
How does Hadoop process unstructured data?
.
In respect to this, how is unstructured data processed?
10 Steps for Analyzing Unstructured Data
- Decide on a Data Source.
- Manage Your Unstructured Data Search.
- Eliminating Useless Data.
- Prepare Data for Storage.
- Decide the Technology for Data Stack and Storage.
- Keep All the Data Until It Is Stored.
- Retrieve Useful Information.
- Ontology Evaluation.
Also, can hive process unstructured data? Processing Un Structured Data Using Hive So there you have it, Hive can be used to effectively process unstructured data. For the more complex processing needs you may revert to writing some custom UDF's instead. There are many benefits to using higher level of abstraction than writing low level Map Reduce code.
Secondly, how do you load unstructured data in Hadoop?
There are multiple ways to import unstructured data into Hadoop, depending on your use cases .
- Using HDFS shell commands such as put or copyFromLocal to move flat files into HDFS.
- Using WebHDFS REST API for application integration.
- Using Apache Flume.
- Using Storm, a general-purpose, event-processing system.
What is unstructured data used for?
Internally, almost every corporate department uses unstructured data in some form; externally, unstructured data is used to monitor and report on movements of shipments and/or assets with sensors and more. When will businesses use unstructured data? Unstructured data is used in every company and organization.
Related Question AnswersWhat is the best example of unstructured data?
Examples of Unstructured Data Examples include e-mail messages, word processing documents, videos, photos, audio files, presentations, webpages and many other kinds of business documents.How do you analyze unstructured data?
When analyzing unstructured data and integrating the information with its structured counterpart, keep the following in mind:- Choose the End Goal.
- Select Method of Analytics.
- Identify All Data Sources.
- Evaluate Your Technology.
- Get Real-Time Access.
- Use Data Lakes.
- Clean Up the Data.
- Retrieve, Classify and Segment Data.
What is an example of structured data?
Examples of structured data include names, dates, addresses, credit card numbers, stock information, geolocation, and more. Structured data is highly organized and easily understood by machine language. Those working within relational databases can input, search, and manipulate structured data relatively quickly.What are the sources of unstructured data?
Unstructured data sources are information assets that are governed by IBM® StoredIQ®. Asset types include instances, infosets, volumes, and filters. Unstructured data sources deal with data such as email messages, word-processing documents, audio or video files, collaboration software, or instant messages.Are images unstructured data?
Unstructured data is all those things that can't be so readily classified and fit into a neat box: photos and graphic images, videos, streaming instrument data, webpages, PDF files, PowerPoint presentations, emails, blog entries, wikis and word processing documents.How unstructured data is stored in HDFS?
Data in HDFS is stored as files. Hadoop does not enforce on having a schema or a structure to the data that has to be stored. This allows using Hadoop for structuring any unstructured data and then exporting the semi-structured or structured data into traditional databases for further analysis.Does Hadoop store data?
On a Hadoop cluster, the data within HDFS and the MapReduce system are housed on every machine in the cluster. Data is stored in data blocks on the DataNodes. HDFS replicates those data blocks, usually 128MB in size, and distributes them so they are replicated within multiple nodes across the cluster.How do you deal with unstructured data?
How to Deal With Unstructured Data- Work with a partner.
- Evaluate the value of your data, and clean your records.
- Take a random sample and create a “dictionary.” Analyzing the entire text file of your data manually is a virtually impossible task—or at least an incredibly time-intensive one.
- Clean the entire dataset.