2 Answers. To check if Apache-Flume is installed correctly cd to your flume/bin directory and then enter the command flume-ng version . Make sure that you are in the correct directory by using the ls command. flume-ng will be in the output if you are in the correct directory..
In this way, how do you run flume?
Starting Flume
- To start Flume directly, run the following command on the Flume host: /usr/hdp/current/flume-server/bin/flume-ng agent -c /etc/flume/conf -f /etc/flume/conf/ flume.conf -n agent.
- To start Flume as a service, run the following command on the Flume host: service flume-agent start.
Also, how do I stop flume agent? 2 ways to stop the Flume agent:
- Go to the terminal where Flume agent is running and press ctrl+C to forcefully kill the agent.
- Run jps from any terminal and look for 'Application' process. Note down its process id and then run kill -9 to terminate the process.
In respect to this, what is a flume agent?
A Flume event is defined as a unit of data flow having a byte payload and an optional set of string attributes. A Flume agent is a (JVM) process that hosts the components through which events flow from an external source to the next destination (hop).
Why is flume used?
HDFS is a distributed file system used by Hadoop ecosystem to store data. The purpose of Flume is to provide a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store.
Related Question Answers
What is difference between flume and Kafka?
Kafka can support data streams for multiple applications, whereas Flume is specific for Hadoop and big data analysis. Kafka can process and monitor data in distributed systems whereas Flume gathers data from distributed systems to land data on a centralized data store.Is it possible to write an event value to a single channel?
Answer: Basically, to handle multiple channels, we use Channel selectors. Moreover, an event can be written just to a single channel or to multiple channels, on the basis of Flume header value. By default, it is the Replicating selector, if a channel selector is not specified to the source.What is Avro format?
Avro is a row-based storage format for Hadoop which is widely used as a serialization platform. Avro stores the data definition (schema) in JSON format making it easy to read and interpret by any program. The data itself is stored in binary format making it compact and efficient.What are non flume components?
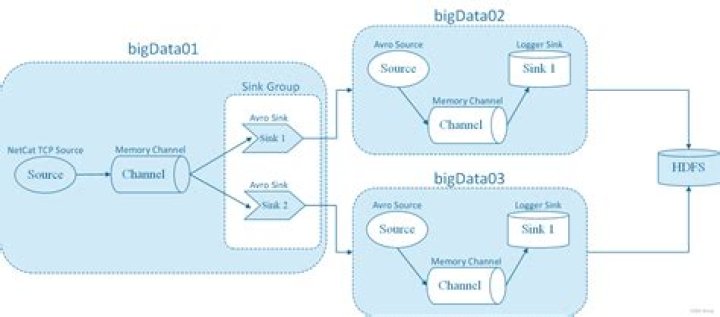
As shown in the diagram a Flume Agent contains three main components namely, source, channel, and sink. - Source.
- Channel.
- Sink.
- Interceptors.
- Channel Selectors.
- Sink Processors.
What is multi hop flow?
Multi-hop Flow Within Flume, there can be multiple agents and before reaching the final destination, an event may travel through more than one agent. This is known as multi-hop flow.Which type of channel will provide high throughput?
Channels are typically of two types: in-memory queues and durable disk-backed queues. In-memory channels provide high throughput but no recovery if an agent fails. File or database-backed channels, on the other hand, are durable.How do I restart flume?
If you wish to completely reset Flume, including resetting all Preferences, Flume Pro status, caches and account information, hold down the ? (OPTION) key as soon as you launch Flume. You will be asked to confirm that you wish to reset Flume.What are the valid sinks of Apache Flume?
Also, we will see types of Sink in Flume: HDFS Sink, Hive Sink, Logger Sink, Thrift Sink, IRC Sink, File Roll Sink, HBase Sink, MorphlineSolrSink, ElasticSearchSink, Kite Dataset Sink, Flume Kafka Sink, HTTP Sink, Custom Sink in flume, Apache Flume Avro Sink example to understand well each and every Apache Flume Sink.What is Sqoop and Flume?
The major difference between Sqoop and Flume is that Sqoop is used for loading data from relational databases into HDFS while Flume is used to capture a stream of moving data. Learn Hadoop to become a Microsoft Certified Big Data Engineer.What is the latest version of sqoop?
Apache Sqoop Latest stable release is 1.4. 7 (download, documentation). Latest cut of Sqoop2 is 1.99.What is flume in irrigation?
Water Rights flumes are concerned with the overall apportionment of water from an irrigation canal / channel or some other source of surface water. Here a specific right to a set amount of water has been assigned to a user. For Water Rights applications, Parshall and Cutthroat flumes are commonly used.What is zookeeper in Hadoop?
Apache Zookeeper is a coordination service for distributed application that enables synchronization across a cluster. It is used to keep the distributed system functioning together as a single unit, using its synchronization, serialization and coordination goals.Is sqoop an ETL tool?
Sqoop (SQL-to-Hadoop) is a big data tool that offers the capability to extract data from non-Hadoop data stores, transform the data into a form usable by Hadoop, and then load the data into HDFS. This process is called ETL, for Extract, Transform, and Load. Like Pig, Sqoop is a command-line interpreter.What is the difference between Kafka and spark?
Features of Kafka vs Spark Data Flow: Kafka vs Spark provide real-time data streaming from source to target. Kafka just Flow the data to the topic, Spark is procedural data flow. Data Processing: We cannot perform any transformation on data wherein Spark we can transform the data.What is the difference between Kafka and storm?
2) Kafka can store its data on local filesystem while Apache Storm is just a data processing framework. 3) Storm works on a Real-time messaging system while Kafka used to store incoming message before processing. 10) Kafka is a great source of data for Storm while Storm can be used to process data stored in Kafka.What is the difference between Pig and Hive?
Pig vs. Hive 2) Hive Hadoop Component is used for completely structured Data whereas Pig Hadoop Component is used for semi structured data. 4) Hive Hadoop Component is mainly used for creating reports whereas Pig Hadoop Component is mainly used for programming. 11) Pig supports Avro whereas Hive does not.Is Kafka open source?
Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.Is Hadoop free?
Generic Hadoop, despite being free, may not actually deliver the best value for the money. This is true for two reasons. First, much of the cost of an analytics system comes from operations, not the upfront cost of the solution.